Playing R with Rammstein texts can be fun when the outcomes are unexpected, and you get plots like

Gut, better. We might even see:
How do we manage making "das Gute" appear?
From general to keyword plots
In the plot based on all the co-occurrences in Rammstein song texts, we can identify a center on the left-hand side:

The meaningful central terms seem to be
"Lust", "Deutschland", "Liebe", "ich", "du", "kalt" and "gut". Choosing these words as keys, we can plot a new picture.

What do we see? There is a clear "ich" - "du" axis. "Liebe" appears together with "ich" and "du", well. But "Lust" seems to be mainly referred only to "ich", as well as "kalt".
Into the contexts
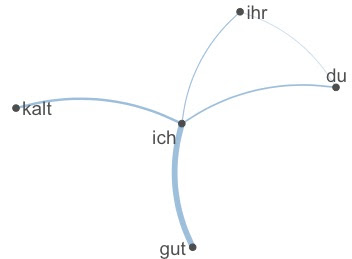
Finding "kalt" surprising, even at the border of a net with "ich", "du". "Liebe", "Lust", I searched for the occurrences of this adjective. While the noun, "Kälte" does not appear at all, a KWIC-search gives 32 occurences of "kalt" instead. We can transform the immediate context (window= 10) into a matrix, count and plot the co-occurences.

The connection between "ich" and "kalt" looks interesting and might be opposed to "ihr" and "heiß", but we are talking about very low absolute frequencies.
feature frequency rank docfreq group
1 kalt 122 1 19 all
2 ich 47 2 25 all
3 heiß 20 3 5 all
4 du 18 4 9 all
5 ihr 18 4 7 all
6 seid 18 4 5 all
7 deutschland 16 7 4 all
8 amour 12 8 3 all
9 ende 10 9 7 all
10 lust 10 9 10 all
Anyway, it might be interesting drawing similar context plots for "ich", "du", "Liebe" and "Lust".
The context of the "personal pronoun" (in fact it is a deictic, an indicating, term (Coseriu)) "ich" seemingly does not reveal surprises. "ich", "du", "Lust", "Liebe" again.

But where does the adjective "gut" come from?
Focussing on words of interest, the importance of "gut" becomes clearer:
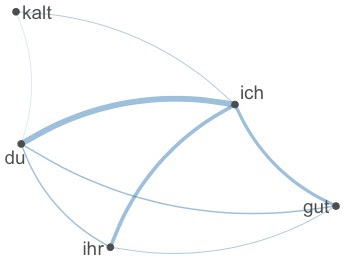
Partly, this may be caused by the repetitions in the famous song "Du riechst so gut". But the link between "ich" and "gut" seems to be stronger. Indeed, the 43 appearances of "gut" are distributed among 17 different songs. Without "riechst" (31 occurrences!), within the context of "gut", we get:
topic1 topic2 topic3 topic4
[1,] "ich" "tut" "ich" "ich"
[2,] "du" "ich" "du" "puppe"
[3,] "ihr" "hört" "gut" "ab"
[4,] "kind" "schreit" "riechst" "kopf"
[5,] "schonste" "tu" "steig" "ja"
[6,] "blut" "weh" "geh" "reiß"
[7,] "giftig" "leid" "hinterher" "geht"
[8,] "dass" "himmel" "finde" "beiß"
[9,] "seh" "gesicht" "gleich" "hals"
[10,] "ach" "ende" "warte" "dam-dam"
Topic analysis should be done more extensively.
Reading words like "ach", "schrei", "giftig", "Leid": We might consider a sentiment analysis. The triangle "ich", "du" and "gut" probably does not give the definitive analytical insight.
For now, a context search for "Lust" and "Liebe" has to be enough.
The complete Lust plot

But, talking about contexts, "Lust" can be eliminated. Only with the keywords:

In (very low) numbers:
Feature co-occurrence matrix
ich du kalt gut
ich 33477 259 2590 259
With the keyword "Liebe", again "ich" is central:

If I had lemmatized the tokens, "lieben" and "liebe" would have been one point.
Without "Lust" and "Liebe":
Nice, is it not? In numbers:
features du ihr ich gut kalt
du 179 352 1179 18 72
ihr 0 214 804 12 56
ich 0 0 23710 3973 1697
gut 0 0 0 225 154
kalt 0 0 0 0 224
In the field of "Liebe", "ich" is good, not you.
In the field of "Lust", "ich" is "kalt", while "du" does only rarely appear. Is this Rammstein?
A last glimpse at "du": 207 entries, and still "du hast" is dominating? Only 13 "du" are found in the famous song.

There is something interesting to be investigated. For now, the "du" context without "du":

In numbers?
features ich ihr gut kalt heiß
ich 17023 2960 17760 6845 10915
In the field of "du", "ich" becomes "gut" and "heiß". Reflect.
technically
everything is done with R quanteda here, see Benoit et.al.
context search
kontext1 <- kwic(toks_fund, "kalt", case_insensitive = TRUE, valuetype = "glob", window = 10)
context into matrix
dopo1 <- kontext1$post
dopom1 <- quanteda::tokens(dopo1)%>%
dfm()
pre1 <- kontext1$pre
prem1 <- quanteda::tokens(pre1)%>%
dfm()
#now bind the two matrices and, because of overlapping #columns, compress
umfeld <- cbind(dopom1, prem1)%>%
dfm_compress()
relative frequency
clean_rel <- dfm_weight(umfeld, scheme = "prop")
textstat_frequency(clean_rel, n=10)
Topic analysis trial
for (k in 3:17) {
fund_lda <- textmodel_lda(umfeld, k)
print(terms(fund_lda, 10))}
Commenti
Posta un commento